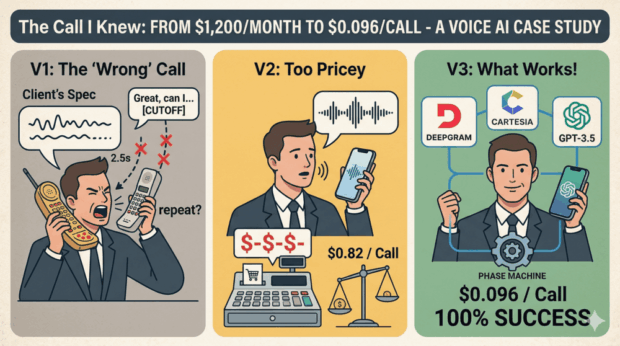
A client came to us with a specific technical requirement: build a phone ordering AI using Twilio Voice API and webhooks. Standard stack. Clear spec.
We had experience with similar systems and advised against the approach — webhook-based voice AI introduces turn latency that breaks the conversational experience. We recommended a streaming architecture instead.
The client wanted to verify this for himself. We built exactly what he specified.
The first round of testing confirmed what we had predicted: 1.7-second pauses after every customer utterance, a 68% order completion rate, and systematic failures whenever customers tried to interrupt or correct themselves mid-sentence.
After seeing the recordings, the client asked us to take full ownership of the architecture. We rebuilt the system twice more — through an OpenAI Realtime API integration that delivered excellent quality but at 7x the target cost, and finally to a LiveKit-based architecture that hit both reliability and cost targets.
The Final Numbers
- Cost per call: $0.096 (target was $0.08–$0.12)
- Order completion rate: 100% in latest test rounds
- Average call duration: 55 seconds
- Architecture: LiveKit + Deepgram + GPT-5.4-mini + Cartesia
The Principle Behind the Architecture
The most important decision in the final system was not the choice of providers. It was separating conversation flow control from language interpretation.
Earlier versions gave the language model control over the conversation flow. Even with carefully engineered prompts, the model occasionally skipped required steps, repeated questions, or produced outputs inconsistent with the source data. A prompt is an instruction, not a guarantee.
The production architecture uses a deterministic phase machine for flow control — a pure function that takes current order state and returns the current phase and permitted transitions. The model’s role is constrained: interpret what the customer said, call the appropriate tool. All outputs are validated against authoritative data before reaching the customer.
This separation — deterministic logic for process control, AI for language understanding — is the same principle we apply to regulated deployments. It is what makes behaviour auditable, predictable, and correctable when something changes.
The gap between a compelling AI demo and a production-grade system is rarely about the model. It’s about architecture: who controls the process, where validation happens, what the model is and isn’t permitted to do.
What This Means in Practice
For organisations evaluating AI in operational or regulated contexts — onboarding flows, claims processing, customer service, compliance monitoring — the architecture questions matter more than model selection. Getting them right from the start avoids the remediation costs of fixing non-deterministic behaviour after deployment.
We build AI systems with these constraints as defaults. If you’re assessing AI for a process where reliability, auditability, and cost predictability are requirements — we’d be glad to talk through the architecture.
Leave a Reply
You must be logged in to post a comment.